 |
| Funnel plot from Dubben & Beck-Bornholdt showing the publication bias in publications about publication bias. |
Thanks to TED and Ben Goldacre, a doctor and epidemiologist, for showing me the best graph ever in his TED-talk: Battling Bad Science. It is the publication bias of publications on publication bias (Dubben & Beck-Bornholdt, BMJ, 331, August 2005, 433-434). Amazingly it is more skewed than most similar graphs in medicine where the publication bias is often held up as the scourge of science, and can be used to put any effect of treatment in doubt.
Now let's turn to our favourite field, hypertension. First we can look at something where we don't expect there to be a difference. For example Angiotensin Receptor Blockers (ARB) compared to Angiotensin Convertin Enzyme Inhibitors (ACEi). Some additional positive effect was expected from ARBs since they only block the evil, AT1, receptor while endogenous Angiotensin II (AngII) would still be able to activate the good, AT2, receptor. Results to this effect have been found in experimental studies, and in initial observational studies. In 2008, Matchar and collaborators reported a meta analysis of head-to-head trials of ARB vs. ACEi (Matchar et al. Ann Int Med. 148 (1) January 2008, 16-29). In their forest plot you first see the observational studies, and they do favour ARBs slightly. Then follows the 19 randomized controlled trials and the average effect is squarely on the identity line, there is no difference in mortality or cardiovascular events between ARBs and ACEi.
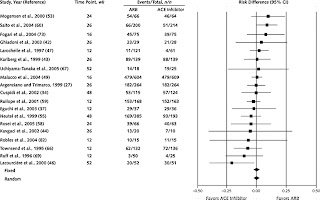 |
| Forest plot from adapted from Matchar et al to show publication bias. |
In clinical medicine today, pre-publication of the protocols and end-points of all clinical trials should pretty much remove publication bias. This may be what we see in the above plot. In basic science and, let's say, publication bias publishing this may still be a problem. In basic medicine the studies are not huge, pre-planned, things that any journal would want to pre-publish. The research is in its search for mechanisms much more of a chain of findings, each building upon the previous. Just one article will often describe as many studies as one of the above meta analyses. In that way they are often more solid than your single clinical trial because the basic finding is repeated several times for each new sub-experiment. At the same time they are more prone to bias by the research group, lab and model. That is, experimental studies should not be generalized outside of the lab where the experiments were performed or the model they were performed in unless you re-do them in another lab with another model. And then, they are true in two models and labs.


No comments:
Post a Comment